Financial Document Research System
The Challenge
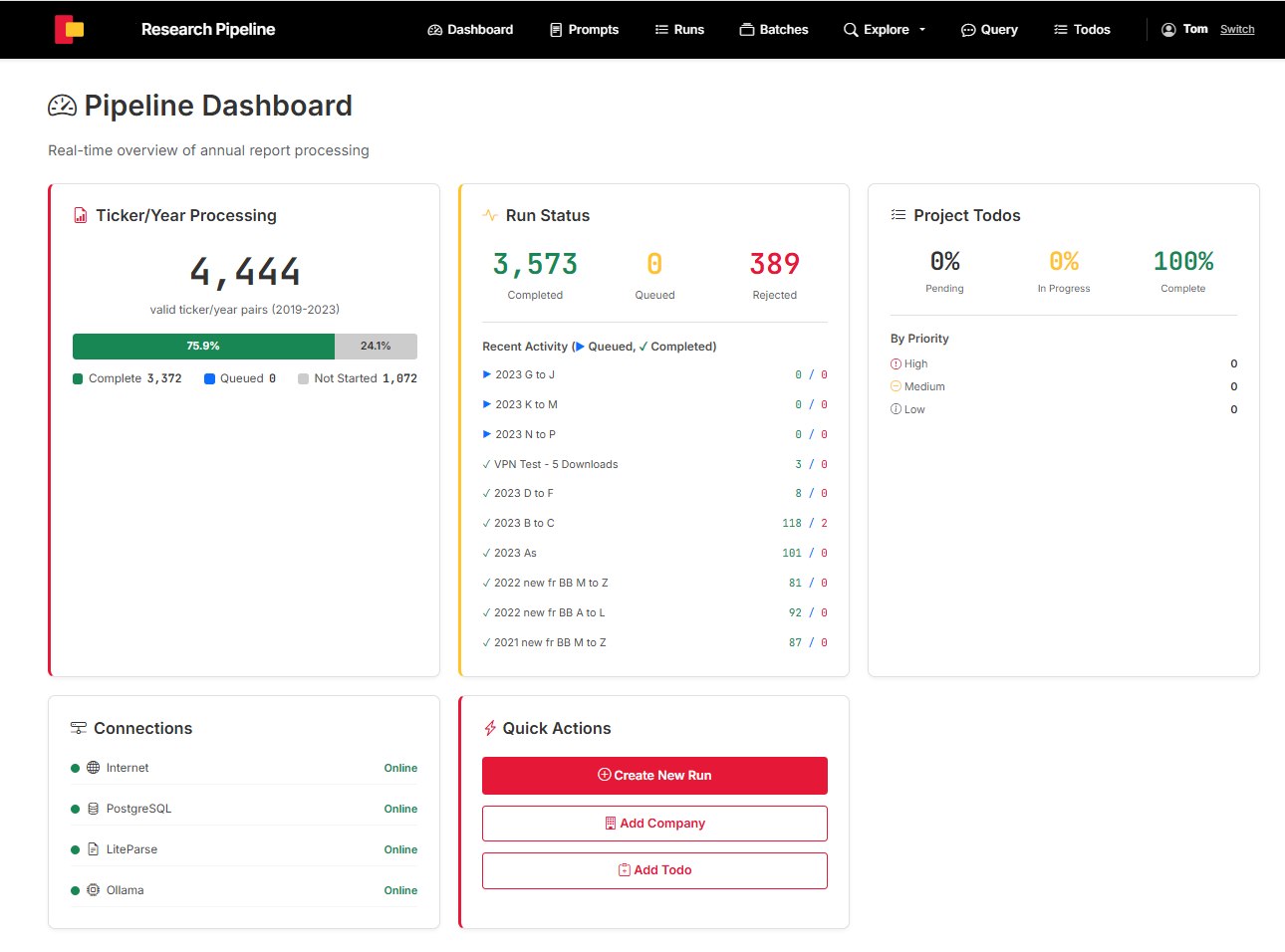
A university research team needed to find, retrieve, and extract specific accounting data from the annual reports of approximately 850 publicly listed companies, across 5 fiscal years — over 4,400 reports in total.
Each report required searching for the correct document online, downloading the PDF, then manually locating and extracting 18 specific data points. Previous iterations of this research had shown that each report took roughly 10 minutes of focused work to process, and a researcher could only sustain that pace for a few hours before both productivity and accuracy began to decline.
The math was daunting: 4,400+ reports at 10 minutes each meant approximately 700 hours of manual work — effectively 6 to 9 months of dedicated effort for a single research cycle. And with accuracy degrading over time, the quality of the extracted data was always a concern.
The Solution
We built a custom research pipeline that combines AI and purpose-built tooling, using each where it is strongest:
1. AI-Driven Search & Selection
AI evaluates search results from public sources, identifies the correct annual report for each company-year pair, and selects the best download option — eliminating hours of manual searching.
2. Local PDF Parsing
In-house parsing infrastructure extracts text from the downloaded PDFs — faster, cheaper, and more reliable than sending entire documents to an AI service.
3. AI Data Extraction
AI reads the parsed text and extracts the 18 target data points from each report — accounting values, commentary, and contextual notes — with source page citations for verification.
4. Semantic Search (RAG)
All parsed report text is vector-embedded and stored in PostgreSQL with pgvector. Researchers can query the full corpus in natural language — cross-company comparisons or single-company deep dives.
The system includes a full management dashboard for monitoring pipeline progress, batch processing, run status, and a web-based query interface where researchers type questions and get answers with source citations.
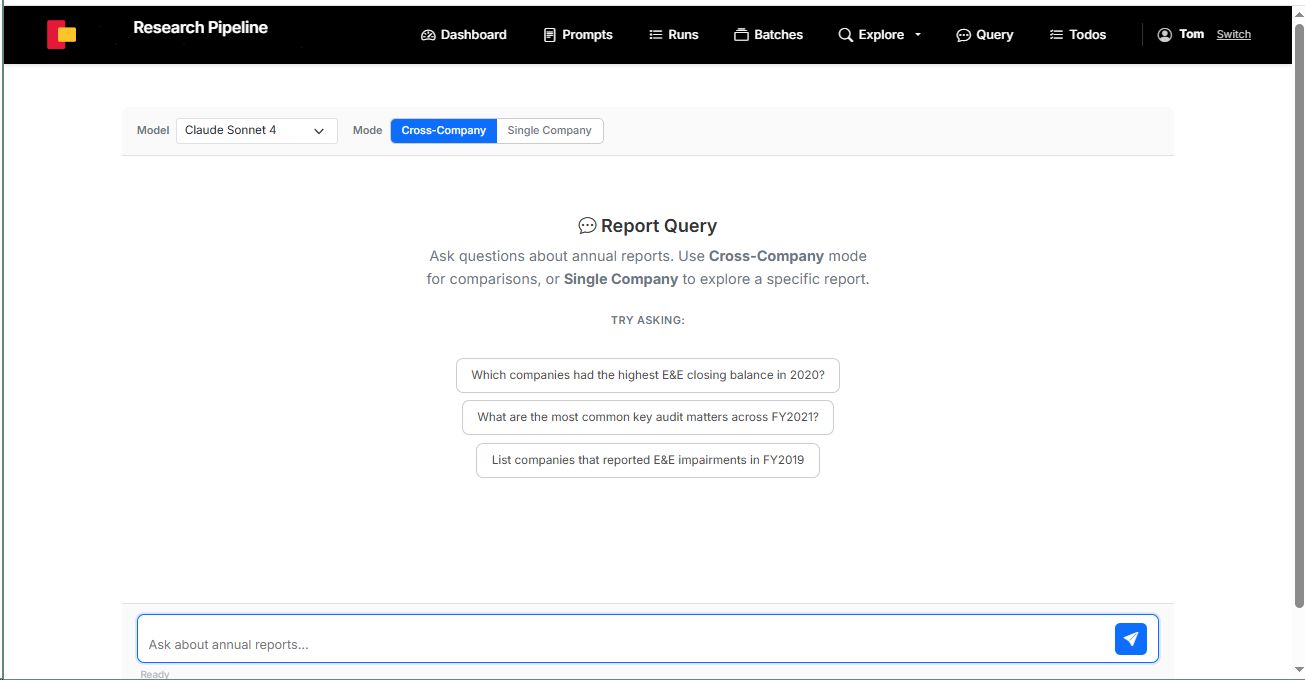
The query interface supports cross-company comparisons and single-company exploration with natural language questions.
The Results
4,444
ticker/year pairs processed
~700 hrs
of tedious manual work avoided
18
data points extracted per report
- ✓ Months of tedious, repetitive manual work replaced by an automated pipeline
- ✓ Consistent extraction accuracy across all reports — no fatigue-related decline
- ✓ Every extracted value includes a source citation with page number for verification
- ✓ Parsed data can be re-analysed to extract new data points beyond the original spec — no need to reprocess the source documents
- ✓ Full corpus is searchable using both traditional keyword search and AI-powered semantic search
- ✓ Pipeline is reusable — adding new fiscal years or companies is incremental, not a restart
Technology
Have a similar challenge?
If your team is spending hours extracting data from documents, searching through reports, or doing repetitive research — there's probably a better way. Let's talk.
Get in Touch